本文根据《Journal of the American College of Cardiology》上曾发表的一篇文章《Making Sense of Statistics in Clinical Trial Reports》,来全面而具体地说明临床试验论文中,各种类型数据与结果使用图表的正确展示方法。
本文将着重介绍基线数据、试验信息以及结局数据中二分类频数资料和计量资料的展示方法。
一、基线(Baseline)数据展示
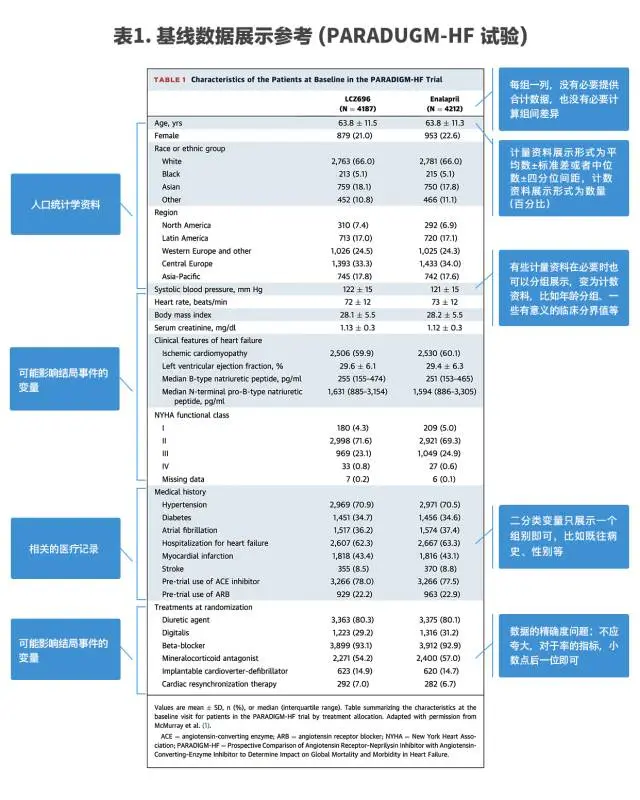
基线(Baseline)数据是所有类型的试验所必须要提供和展示的信息,具有描述研究所纳入的样本特征、标示研究所关注的变量等重要作用。
基线(Baseline)数据的展示多以表格的方式,以各种变量的名称为表格每行的标题,而不同的组名为表格每列的标题,需要涵盖的变量包括人口学资料、可能影响结局事件的变量以及相关的医疗记录,每列提供一个组别的数据,在RCT中没有必要提供合计数据或进行组间差异比较。
下方提供一个研究的表格作为范本,数据的展示方法、可能遇到的情况及相关注意事项标注在相应位置(表1)。
二、试验信息(Trial profile)展示
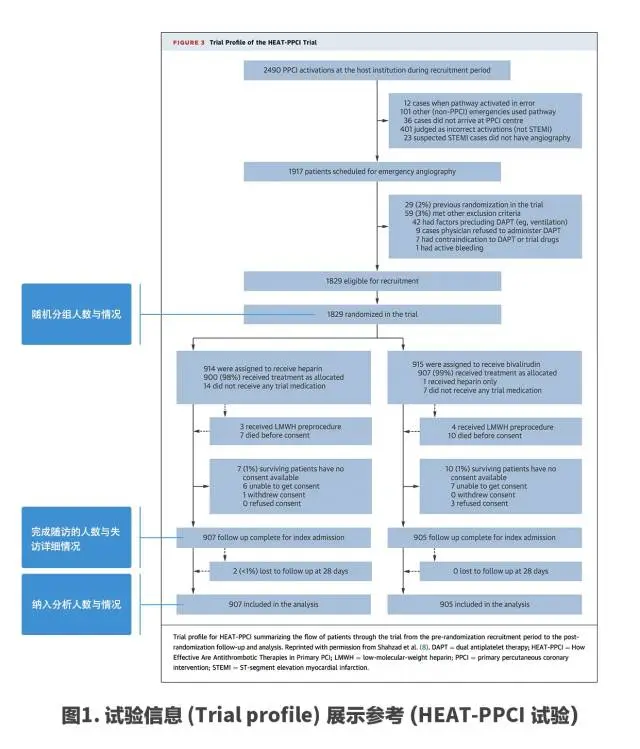
试验信息(Trial profile)也是需要展示的部分,用以清晰直观的描述在试验进程中各个时间点的操作,以及在各个操作过后各组人数的变化及原因,方便读者对研究有直观的了解。
试验信息(Trial profile)多以流程图的形式进行展示,按照时间和操作顺序排列,清晰列出每一部分的人数,需要展示的重要操作节点至少应包括随机分组、完成随访及数据分析。
下图展示的是一个研究中所提供的试验信息(Trial profile)图,作为示例范本供参考,可行的展示方式多种多样,样式不用局限于示例,但主要信息要清晰地提供出来(图1)。
三、二分类频数资料的结果展示
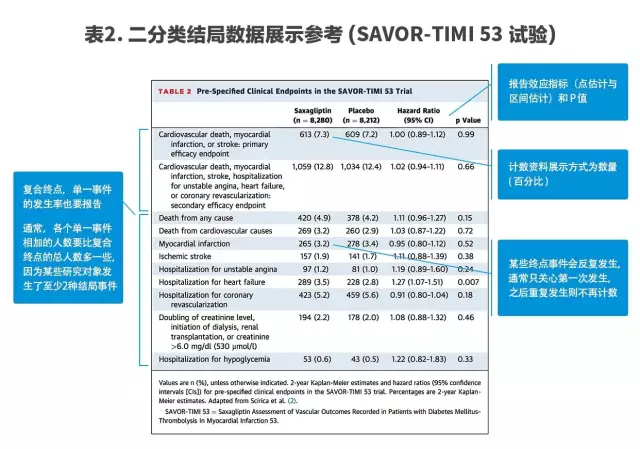
二分类频数资料在试验研究中经常被涉及,例如:性别、各种事件发生与否等,是结果展示中的重要组成部分,主要结局数据表格和副作用表格均包含大量二分类资料。
在主要结局数据表格中,与基线(Baseline)数据形式类似,同样是以各种变量或事件的名称作为表格每行的标题,而不同的组名为表格每列的标题,不同之处在于需要增加两列,分别报告效应指标的大小和P值。
值得注意的是,在事件的展示中,许多研究的主要终点为复合终点,此时需同时在下方依次提供各个事件单独发生的数量与百分比。
效应指标需要包括点估计值与区间估计。在这里,强调一下区间估计的重要性,并解释一下点估计值与区间估计的关系:点估计可以得到一个具体的数值,表示结果的大小,而这一结果存在很大程度的不确定性,区间估计即可表达这种不确定性,通常用95%置信区间(Confidence Interval)。
之所以选择95%,主要是为保证研究的一致性,方便与他人研究进行比较,因为大部分的研究都选择了95%这一数值;同时,与通常设定的显著性水平0.05保持一致,方便与P<0.05进行关联。样本量越大,这种不确定性越小,置信区间越窄,点估计值估计越精确。因此,单独报告点估计值是不够严谨的,需要同时报告区间估计的结果。
下图同样提供一个研究的表格作为范本,注意事项标注在旁(表2)。
对于研究的效应分析可以用到多种不同的效应指标,表3总结了各个效应指标的概念及计算方法。通常,两个组别时,先列好数据的四格表,计算发生率,再进行相应的效应指标计算。
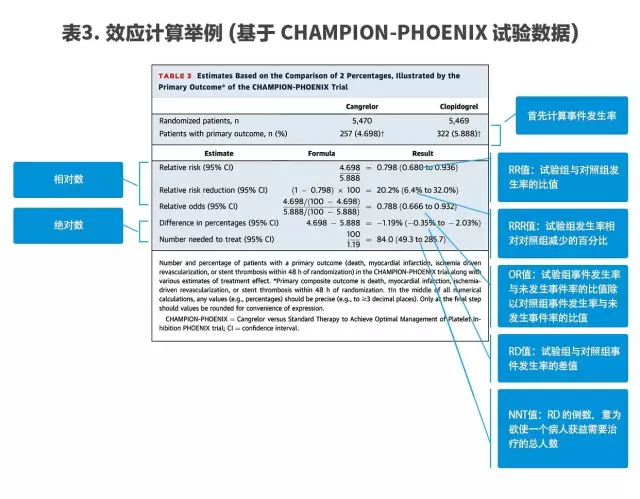
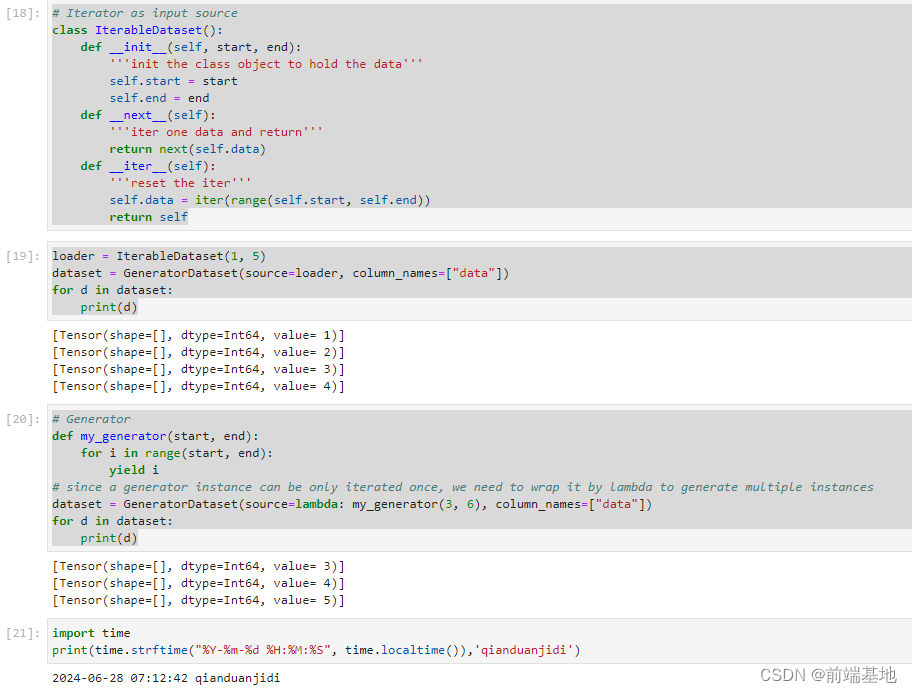
效应指标包括绝对数(如危险度差(Risk difference, RD/Difference in percentages)、需治疗人数(Number needed to treat, NNT)等)和相对数(如相对危险度(Relative risk, RR)、相对危险降低(Relative risk reduction, RRR)和比值比(Odds ratio, Relative odds, OR)等)两类。相对数指标具有统计学优点,且对于不同类型的人群的一致性较好,结果易于推广,而绝对数指标则更有实际价值和意义。
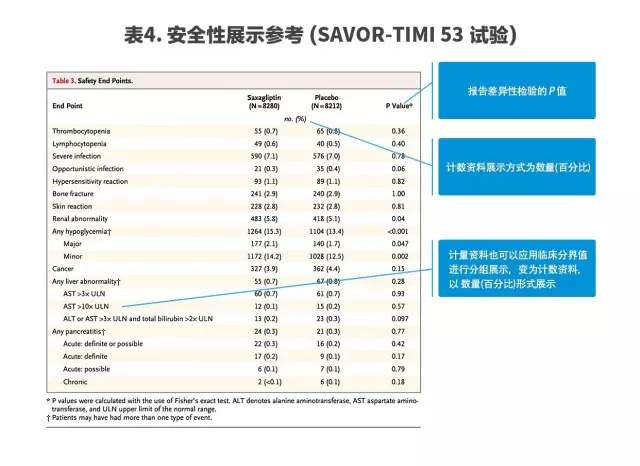
此外,除了要报告详细记录和主要结局指标外,安全性信息也要进行报告,安全性表格也多为二分类资料。
与主要结局事件表格类似,同样是以各种变量或事件的名称为表格每行的标题,而不同的组别为表格每列的标题,不同之处在于只需要进行组间差异性检验,报告P值的大小。
下图即为一个研究中所展示的安全性表格,作为内容与样式的参考(表4)。
四、计量资料的结果展示
1. 单个时间点的组间均值比较
在分析定量结局指标时,一般比较常见的分析策略就是直接比较不同干预组结局指标的组间差异。然而,考虑到多数情况下这些结局指标都会在基线时被测量,一个更加合理的方法是比较结局指标相对于基线的平均变化值。
但是这里也同样存在一个Bug——这种变化值往往会受到基线水平的影响,比如我们常说的“向均数回归(regression to the mean)”——在同等的干预条件下,那些结局指标基线水平比较高的研究对象可能会获得更大的下降。为了解决这样问题,就需要另一种统计学分析方法——协方差分析(ANCOVA),即在比较结局指标变化值时调整其基线水平。
来看一个实例,SYMPLICITY HTN-3研究[6]是一项随机、双盲、假手术对照试验,共招募 535 例严重难治性高血压患者,按照 2:1 进行随机分组,分别进行去肾交感神经术或假手术治疗。研究主要终点为治疗6个月时患者收缩压(SBP)下降。
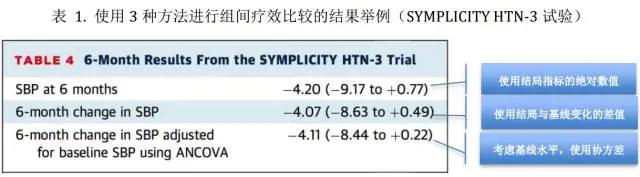
如表1所示,首先进行去肾交感神经术和假手术治疗组6个月时SBP的组间比较,其次在比较两组SBP 6个月的变化值时考虑是否调整其基线水平。可以比较明显地看到第一种组间比较得到的95%CI比后两种情况更“宽”,而在调整了SBP基线水平的第三种情况比较时95%CI最“窄”。
比较遗憾的是,上述95%CI仍跨越“0”,即组间差异无统计学意义。提示去肾交感神经术与假手术相比并未减少难治性高血压患者的6个月时收缩压水平。
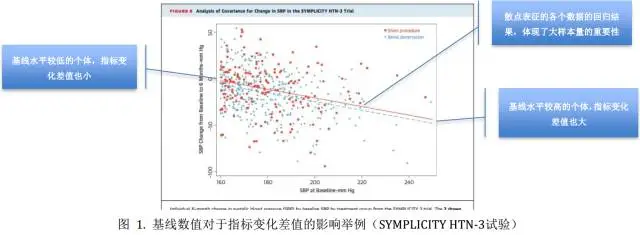
调整SBP基线水平真的有必要吗?下图中去肾交感神经术和假手术治疗组两条回归线显示,两组中基线SBP水平较高的研究对象,6个月后SBP下降值也更大。如果不进行SBP基线水平调整,实际的效应值可能会被错误估计(4.07 vs. 4.11adjusted mmHg)。
此外,从下图中也可以明确另一点,即不同研究对象的研究结果差别很大,这也是为什么临床试验通常需要纳入足够的研究对象(样本量太少,结果可能并不稳定)。
细心的小伙伴可能会提另外一个问题,实际分析中是选择结局变化的差值,还是选择相对于基线水平的变化百分比?从统计上讲,这时候就要看哪种情况更适合使用协方差分析。(详见:手把手教你协方差分析的SPSS操作!)
2. 多个时间点计量数据的分析与结果展示方法
以上我们讨论了,如何利用结局指标的基线数据来使干预措施的临床疗效估计更为合理。实际上,很多时候一个临床研究在设计数据收集时,往往不会只收集开始(基线)和结束(随访终点)两个时间点的数据。当遇到结局指标多个时间点数据时,就需要采取不同的方法,当然也取决于研究目的。
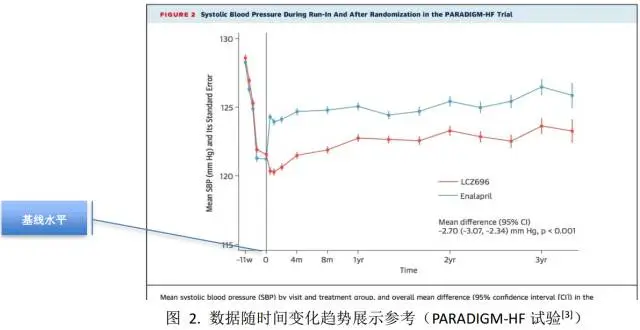
①两组均值随时间的变化趋势
多个时间点的计量数据可以以时间为横坐标、指标数值为纵坐标绘制折线图展示,下图为一项研究的结果图,每个时间点都描绘了均值与标准误(下图)。
② 不同下降率(或升高率)的组间比较
许多研究的结局指标中,后续时间点较基线时的变化数值所占百分比(下降率或升高率)具有重要的临床意义,比如在呼吸系统功能损伤的研究中用力肺活量的下降率,此时可计算不同时间点的结局指标下降率或升高率,再进行组间比较及后续分析。
③ 在随访过程中某一特定时间点的独特价值
如在18个月时检测糖化血红蛋白来评价一种糖尿病药物的疗效,这样的情况下,特定时间的数据应着重分析。
因为多个时间点的计量资料往往存在相关性,不同于一般的统计分析方法(要求各数据彼此相互独立),此时应该选择重复测量分析。(详见:SPSS:单因素重复测量方差分析(史上最详细教程))
3. 计量资料呈偏态分布的分析方法
有时候计量资料的数据呈偏态分布,此时组间均值比较的传统分析方法可能受一些极端值的影响而扭曲,此时可以选择如下的处理方法:
① 采取合适的数据转换
例如,将原始数值取自然对数后,数据呈正态分布,此时采用几何均数来进行组间差异的比较。
② 使用非参数检验
非参数检验中,比较常用的是采用中位数对两组疗效进行描述,并用非参数方法(例如常用的秩和检验)对组间疗效差异进行分析可避免极端值的影响。
③ 设定特定的临界值,将原来的连续性变量转换为二分类变量
例如,计算超过肝脏功能指标上限数值的人数占总人数的百分比,这时采用卡方检验比较组间的百分比有无差异即可。
参考文献
-
J Am Coll Cardiol 66(22):2536–2549
-
N Engl J Med 2014;371:993–1004.
-
N Engl J Med 2013;369:1317–26.
-
Lancet 2014;384:1849–58.
-
N Engl J Med 2013;368:1303–13.
-
N Engl J Med. 2014; 370:1393–401.




![[游戏开发][UE5]引擎学习记录](https://img-blog.csdnimg.cn/direct/a0ee1c2ccf7349128c2c6f29f9b601f1.png)